Hello, I noticed some potentially misleading information in the “Runes and Strings” section of the documentation:
"
Runes and Strings
Strings in Go are encoded using UTF-8 which means they contain Unicode characters. Since the rune type represents a Unicode character, a string in Go is often referred to as a sequence of runes. However, runes are stored as 1, 2, 3, or 4 bytes depending on the character. Due to this, strings are really just a sequence of bytes. In Go, slices are used to represent sequences and these slices can be iterated over using range.
"
In my understanding, since runes are an alias to int32 (which is an explicitly sized integer type), they always occupy 4 bytes, regardless of the character’s UTF-8 encoding size. Therefore, the statement “runes are stored as 1, 2, 3, or 4 bytes” might be misleading.
Suggested Change:
To accurately reflect the behavior of runes in Go, it might be necessary to clarify that while characters within a string may require different numbers of bytes when encoded in UTF-8, runes themselves are consistently represented as 4 bytes.
I don’t know Go well, but my understanding is that this clarification is correct. Runes are always 4 bytes. Maybe a more correct way of saying it would be that “Each character maybe need 1, 2, 3 or 4 bytes to be represented, but are always stored as 4 byte runes”. Maybe?
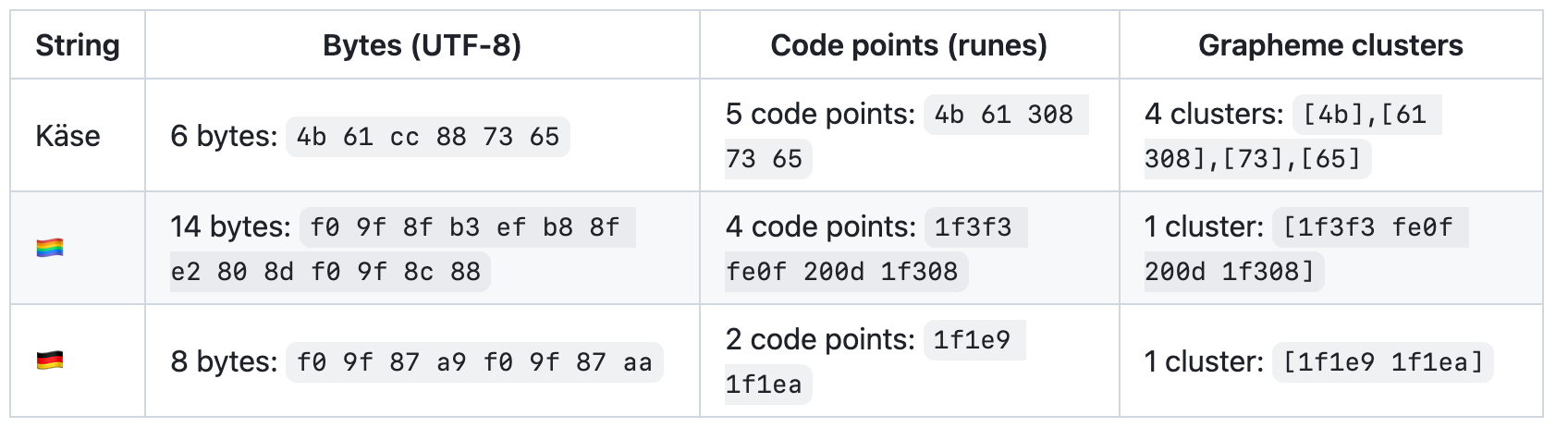
Like the example @kotp shows, the string 你好 contains 2 runes, but if we ask the size in bytes of this string, it has 6 bytes, 3 bytes for each rune. But a string like hello only takes 5 bytes, 1 for each rune/character. So, Go does optimize the space for each rune when it is in a string, and that’s what the copy is trying to highlight.
Perhaps the best correction here would be something like:
Runes in a string are stored as 1, 2, 3, or 4 bytes depending on the character.
However, it’s true that the rune type is an alias for an int32, so individual runes by themselves take 4 bytes always, and the copy does not do a good job at making this distinction.
What about something like:
Strings in Go are encoded using UTF-8 which means they contain Unicode characters. Since the rune type represents a Unicode character, a string in Go is often referred to as a sequence of runes. **While an individual rune always takes 4 bytes (remember, the rune type is an alias for an int32!), runes in strings are stored and encoded as 1, 2, 3, or 4 bytes depending on the unicode character it represents, as some unicode characters need more bytes to be represented than others. Hence, strings can be seen as a sequence of runes, but also as a sequence of bytes. In Go, slices are used to represent sequences and these slices can be iterated over using range.
I feel this clarifies the potential confusion, but I fear it gets into a lot of technical detail that can be overwhelming for some. Maybe it’s worth it?
We might gloss over the detail in the initial statement (there are plenty of programming languages that do lie to you (“everything is an object” says Ruby, yet there are things that are objectively not objects, but a convenient lie that is almost true) but we can do a disservice if the detail is not readily available for clarification).
The details could be an “INFO” style admonishment. It may not be important to get into the details for the exercise at the moment, but at some point, it will be good information to know.
It can! If the string is a single ascii character, it will have a single byte, as encoding any ascii character in utf-8 only takes a single byte.
It’s mostly because the language and the standard library uses runes a lot when dealing with strings. But it’s also true that the language sees strings and sequences of bytes and runes depending on the context.
For instance, indexing operations on strings get the byte, e.g myString[i] gets the i-indexed byte of the string. So, for indexing operations we can say that strings are sequences of bytes.
But looping over a string gets its runes:
for i, r := range myString {
// r is a rune, i is the byte index where the rune r starts
}
There’s also the fact that the standard library package strings used to do common operations on strings also expects runes rather than bytes for operations like checking if a string contains a specific character, string mapping operations, etc…
Converting a string into a slice of bytes or runes is also trivial operation and can be done with []byte(myString) or []rune(myString) respectively.
So, does this mean that it’s allocating an extra 3 bytes per ascii character to convert it to runes when you loop over a string. That’s bonkers!
OK, thanks for explaining all that! I think the key thing then is probably that describing a string as a sequence of runes is a lot confusing (I know that’s common language, but it feels very confusing to me!)
So maybe something like this?
Strings in Go are encoded using UTF-8 which means they contain Unicode characters. Characters in strings are stored and encoded as 1, 2, 3, or 4 bytes depending on the unicode character they represent.
In Go, slices are used to represent sequences and these slices can be iterated over using range. When we iterate over a string, Go converts the string into a series of Runes, each of which is 4 bytes (remember, the rune type is an alias for an int32 !)
I don’t think it means that. Rather it copies the byte into a rune loop variable on each loop iteration. Only a single rune needs to be allocated. It casts on each loop.
Sort of. The loop variable is reused, so not all the memory for all the runes in the string needs to co-exist at the same time.
The magic here is that Go performs utf-8 decoding of each rune on the fly, meaning it looks at the bytes of the string in each iteration and figures out the next grouping of bytes that constitutes a single rune.
What helped me fully understand how Runes work in Go was by using the “unsafe” package, which allow you to work with memory directly.
In the code example below, I first print the number of bytes for the original “multiByteString”. Then I print the bytes for multiByteString that is casted into a slice of runes.
package main
import (
"fmt"
"unsafe"
)
func main() {
multiByteString := "你好" // Chinese characters
//First, printing bytes of original string
fmt.Printf("Byte size of 你好: %v bytes\n", len(multiByteString))
multiByteRuneSlice := []rune(multiByteString)
numBytesFirstRune := unsafe.Sizeof(multiByteRuneSlice[0]) // first element '你'
numBytesSecondRune := unsafe.Sizeof(multiByteRuneSlice[1]) // second element '好'
numTotalBytesOfRuneSlice := numBytesFirstRune + numBytesSecondRune
//bytes for string after casted to []rune
fmt.Printf("Byte size of []rune(你好): %v bytes\n", numTotalBytesOfRuneSlice)
}
The output is as follows
Byte size of 你好: 6 bytes
Byte size of []rune(你好): 8 bytes
…
As you can see, the string (or slice of bytes) of the ‘multiByteString’ prints out 6 since the two Chinese characters only need 3 bytes each in order to be represented. The rune slice on the other hand is 8 bytes, since each rune occupies 4 bytes each, regardless of which character it represents.
I think this detail is important because it highlights the purpose of having runes in go, especially helpful for the learners coming from having a background with a lower level programming language.
I think the Runes chapter could be even more awesome with these updates:
Making sure and explicitly stating that string is like immutable a slice of bytes, not a slice of runes.
The purpose of runes is that when you cast a string to a slice of runes, it allows us to do many convenient things (with examples).
I will likely do this, but will need to do a “normalization” PR first. The current markdown files do not adhere very well to the current "Building Exercism - Markdown specifications document.
Instead of having one PR with both, more difficult to revert for whatever reasons, I will put them up individually.
@kotp Still interested in working on this? Can’t reopen the PRs now, but I’ll gladly accept new ones. I can also take the patch and make the PR myself if you prefer, but I don’t want to take the credit of the work away from you!
One note though: this copy is also present in exercises/concept/logs-logs-logs/introduction.md, the exercise for this concept, so changes also have to be made there.
If you apply the patch, credit will still be given to the author. Git is good like that.
https://patch-diff.githubusercontent.com/raw/exercism/go/pull/2768.patch | git am -3
No work lost and no attribution lost.
You can then apply any corrections, even do a git commit --amend if the changes are trivial and you do not want to accept credit other than review and acceptance.
My worry about credit and attribution was more on the Exercism side rather than Git/Github side. I know the patch can credit the author, and even if it didn’t, one can specify the author of a commit manually (as long as there isn’t a requirement for the commits to be signed). And Github does allow to specify commits with multiple authors.
However, even if credit was given on a commit-by-commit basis, if I were to create the PR, I guess Exercism wouldn’t take that into account when giving out rep. I believe it would just see me creating the PR and merging it and give rep based on that.
I did not know that the author would not get credit from Exercism’s standpoint. I believe I have submitted “2nd party” PR’s, with the belief that it would end up following through.
I guess the e-mail address of the person would be likely the thing to match, rather than the github account, especially if the person has an e-mail account association and not a github account association.