we have an issue concerning the difficulty ratings for our exercises.
We can order them by “feeling”. This is the current method. The downside is, that each author might have a different baseline and might even be out of touch when it comes to seeing these exercises for the first time.
We could try to orient ourselves with some more data. There are exercise completion stats, that might be useful for us.
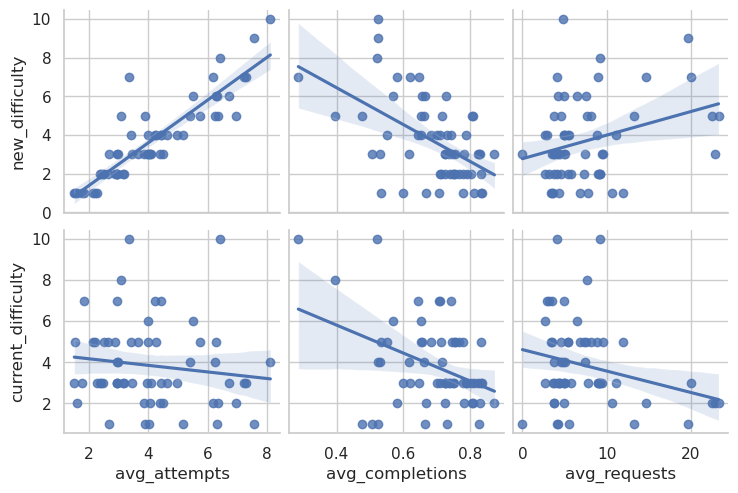
I grabbed the data and ran some calculations with it. I came up with a rating that depends on the average completion rate and the average number of attempts for an exercise. With some min-max-scaling I get the following visualization:
The new rating would indicate, that more attempts make a more difficult exercise (or that the explanation is just not as good, yet). I think that would be an improvement.
In the graph, I used `avg_attemps / avg_completion**1.3*. Thus giving the completion rate more weight. I am not sure if the average mentoring request rate is a good indicator of the difficulty of an exercise, but I would argue, that an exercise that is perceived as easy, might not be forwarded to a code review very often. The new rating reflects this thought to some degree.
A difficult point is the correct scaling. As many people start the hello-world exercise and never finish it, the new system would not rate it as the easiest exercise on the track. Food chain is currently rated with a 7, but the completion rate is very high (for the few people who dare). So it would be downgraded to a 1.
I would like to give users a “weight.” A user that has finished many, many exercises and can’t solve a particular one, would weigh heavier than someone who tried 5 and abandoned them all.
I think self-reporting is difficult. A new user might think every exercise, in the beginning, is difficult, and never get to the later exercises, which they might rate a lot harder. So you would introduce some survivorship bias into the rating system. I think this is already the case with my proposed system, as harder exercises might only be taken on by more experienced users and thus have a higher completion rate.
as an experienced exercism user, I’d see an exercise with difficulty 7 (is 7 “hard” or “medium”?) and think “OK this will require some thought. Hit me!”
a fresh learner would, I assume, not attempt it.
If it had difficulty 1, I imagine the fresh learner would open the “easy” exercise, get thoroughly confused and give up.
I suspect you’re proposing a new rating system for exercises, or perhaps a customized introduction.
Hi vaeng. I see you’ve progressed quite far on the C++ track. This exercise has a stated difficulty of 7/10. 70% of people who start it are able to successfully finish it, so it should not be too challenging for you. Are you ready to start?
One needs to ‘start’ an exercise in order to view the stub and tests.
No need to decide on exact metrics beforehand. If every difficulty judgment is recorded together with the number of previously solved exercises, then the statistical analysis can be easily replaced in the future.
Then I have to explain better
My current proposal to redo the C++ rating is based on the completion rate and the attempt rate.
This is not ideal, and you would still have to rate a new exercise by hand until a certain number of users have tried it, to get some data.
One example of a rating change is the Food chain exercise, which currently sits at 7/10. This particular exercise is solved by a big proportion of people in a few attempts. It thus seems “easy”. I think it is not easier than hello-world, which sits at 1 and would be upgraded to 3 based on the completion and attempt rate.
I think the numbers for Food Chain are biased because the 7/10 scares away beginners and only advanced users dare to try it. This might result in a higher completion rate as opposed to the same exercise with a 2/10 label, which is attempted by a lot more inexperienced users.
I might have to think about how the number of people who started the exercise might play into this. Maybe a “rare” bonus? If only a few people have tried an exercise it would get a higher difficulty rating, because the description might scare them off.