This is part of the exercise overhaul described here:
Basically for each exercise, we want to make sure that it is in the context of a story. Not an elaborate story, but something that helps you imagine a concrete scenario and make it just a bit more interesting.
As an example, instead of just “figure out if a sentence is a pangram”, we reframed the exercise to give a reason why you need to do this (you work for a company that makes fonts, and they want to use pangrams to show off the fonts on their website. https://github.com/exercism/problem-specifications/pull/2215).
I’m trying to come up with ideas for the scenario for the run-length-encoding exercise.
This is what we have, currently:
The instructions for the exercise will basically be the same, we’re just trying to frame the exercise within a scenario that helps make it feel more concrete and interesting.
The questions to kick this off are:
What situations would require minimizing data for
transmission?
storage?
For a given scenario, what is the data that has lots of sequences of the same letter being repeated, making it ideal for run-length encoding?
Any ideas or suggestions?
(/cc @dreig – You were a huge help with the saddle-points exercise. Pulling you in, just in case this is up your alley)
For RLE to be useful, the uncoded data needs to be monotonous. This suggests measurement to me. (Indeed, a television signal is an example of a measurement: by camera.)
In transmission, compression is only useful 1) if you need to transmit lots, or 2) if you need to transmit quick.
I’m thinking of spy submarines and satellites. The former needs to dive again as soon as possible; the latter may have only short timespans in which they are positioned above and can talk to ground stations. The focus on characters does not fit these scenarios very well however.
I’m guessing most LHC data is very boring. Also, there is very much of it: it is cheaper for CERN to transmit (some of) it via physical hard drives rather than over a wire network.
Sadly, it’s historical data. But what about the weather on mars? here’s more updated weather at Gale Crater. Something around encoding it for transmission, or decoding it for reporting?
As I was drifting off to sleep last night, I was also thinking about the combination of space and measurements—especially if there are lots of measurements that are the same most of the time, but that when something happens you need to know quickly. So maybe temperature measurements on a tidally locked moon or something. I feel vindicated by @MatthijsBlom and @BethanyG’s suggestions :)
@glennj I love the idea of using Hamming to do test scores. I’m totally going to run with that. It’s way more approachable than DNA (and we already have DNA other places).
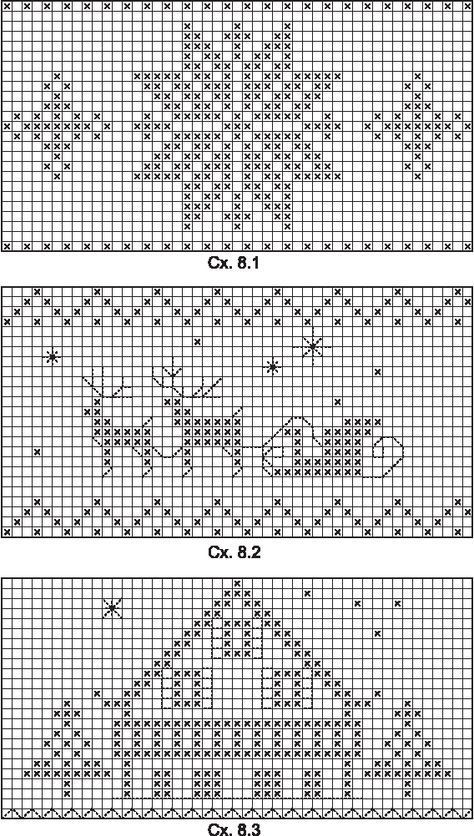
@vaeng I love the knitting patterns! I love that it’s so different, and what we in Norway would call “koselig”. (Also, @MatthijsBlom, thanks for the official name for these types of patterns.)
So, to conclude: I’m stealing the multiple choice thing for Hamming and running with the knitting patterns example for run-length-encoding.
Gezellig is often brought up as an ‘untranslatable’ Dutch word. However, it now seems to me that it is shared in Scandinavian as hyggelig and koselig. All three look a bit like cognates to me, but I cannot find proof.
Happy to contribute! And I thought I would never need my degree in textile engineering ever again after switching to comp science.
I have to chip in with some German term.
Gemütlichkeit (German pronunciation: [ɡəˈmyːtlɪçkaɪt]) is a German-language word used to convey the idea of a state or feeling of warmth, friendliness, and good cheer. Other qualities encompassed by the term include cosiness, peace of mind, and a sense of belonging and well-being springing from social acceptance. The adjective “gemütlich” is translated as “cosy” so “Gemütlichkeit” could be simply translated as “cosiness.”