Dear Isaac,
Sorry, but I feel strongly demotivated by your requests for a detailed diff.
It seems like you are unwilling to go to the exercise and read,
and also unwilling to see the details in the image.
But let me persevere for a while.
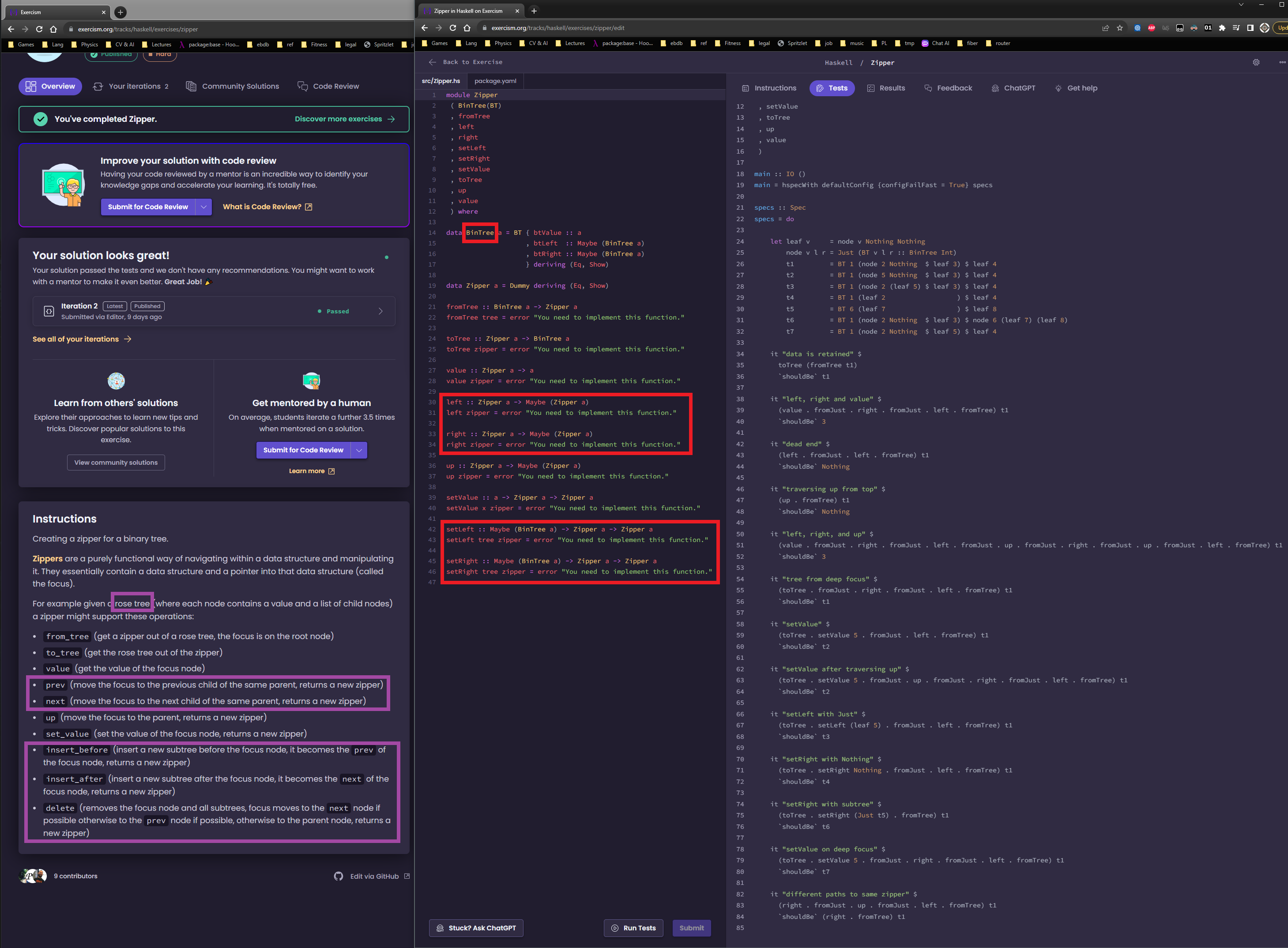
instructions.md file is https://raw.githubusercontent.com/exercism/haskell/main/exercises/practice/zipper/.docs/instructions.md
Zipper.hs file is https://github.com/exercism/haskell/blob/main/exercises/practice/zipper/src/Zipper.hs
In line 3 of the instruction.md, a binary tree type is mentioned once and never more.
The rest of the instruction file discusses an example of a “Rose Tree” and not “Binary Tree”, that is somewhat relevant to the task, but is also confusing.
instructions.md line 13: prev function is introduced, it is absent from the Zipper.hs.
Zipper.hs line 30: left function is introduced instead of prev function of the instructions.md.
instructions.md line 15: next function is introduced, it is absent from the Zipper.hs.
Zipper.hs line 33: right function is introduced instead of next function of the instructions.md.
instructions.md line 19: insert_before function is introduced, it is absent from the Zipper.hs.
Zipper.hs line 33: setLeft function is introduced instead of insert_before function of the instructions.md.
instructions.md line 21: insert_after function is introduced, it is absent from the Zipper.hs.
Zipper.hs line 33: setRight function is introduced instead of insert_after function of the instructions.md.
instructions.md line 23: delete function is introduced, it is absent from the Zipper.hs.
A student can imagine, that a Binary Tree can be represented by a “Rose tree” where each node has at most 2 children.
They can also think that the functions were renamed between instructions.md and Zipper.hs.
But the difference between e.g. functions prev and left is deeper: instructions.md prev description suggests navigating to the left among the sibling nodes on the same level,
whereas Zipper.hs left is expected to descent one level down.
In the absence of comments in Zipper.hs, it is only Tests implementation what can guide a student out of their confusion.
In this context, instructions.md lines 8-25 only cause the confusion.
I have expressed my readiness to edit instructions.md lines 8-25 so that they discuss the relevant example and contain relevant function names and explain relevant function semantics.
Now how explicit is this ?